05 데이터 결합 - Concat, Join, Merge, (차이점, 코드)

데이터 몇 번 다뤄보면서 느낀 게
날것의 데이터는 교수님들 말대로
데이터 전처리 + 그리고 Join이 8 할인 것 같음.
통계는 학부생 때부터 계속 배워서
inner join, outer join 입에서 달달 외는 것 같지만
또 데이터 분석하려고 보면
뭐 쓰지 하고 덜덜 떨고 있는 나 자신 발견.
게다가 concat, join, merge 중에
뭐 써야 할지 혼돈의 도가니
정리하면서 느낀 게 정해진 것은 없고
각자의 기능 차이가 있으니,
케이스에 맞게 쓰는 것이 정답이더라.
무튼 오늘은 데이터 합치는 Merge, Join, Concat차이점에 대해서 정리해보는 시간
Join Me 🦝
01 Join 개념
1/ 수직 결합(SQL의 UNION)
: 행 아래에 붙이는 것

2/ 수평 결합(SQL의 JOIN)
:열 옆에 붙이는 것

02 Concat
01 Concat 기능
- 수직 결합 지원, 조인을 이용한 수평 결합 모두 지원
- 수직 결합의 경우: 칼럼명이 같은 열끼리 합체
- 조인(수평결합)의 경우: full outer join과 inner join 지원
- full outer join이 디폴트(값 지정 안 하면 자동으로 full outer join ㄱㄱ)
- join 기준: index가 같은 행끼리 합체(equi- join)
02 Concat 코드
pd.concat(dataframe 이름들, [key 리스트], axis = 0, join = 'outer')- dataframe 이름들: 합칠 dataframe들을 리스트로 전달
- [key 리스트]: keys = []를 이용해 합친 행들을 구분하기 위한 다중 인덱스 처리
- axis: 0(수직결합) 또는 1(수평결합)
- join: 조인 방식 outer 또는 inner
03 Concat 결과
수직 결합
우리에게 이렇게 3가지 테이블이 있고 요 테이블을 합쳐보자.
코드 결과를 보면, Concat의 기능에 대해서 이해할 수 있을 것이라 믿긔.



df = pd.concat([s_2016, s_2017, s_2018])
df
이렇게 데이터가 정말 '합체'만 된다. index도 기존 꺼 그대로 붙기 때문에 보기가 영 별로다.
ignore_index = True 매개변수를 추가로 넣어주면 기존 index는 drop되고 새 index가 순차적으로 붙는다.
df = pd.concat([s_2016, s_2017, s_2018], ignore_index = True) # 기존 index drop하고 새번호 겟
근데 아마 이 세 가지 데이터를 합칠 때 이렇게 합쳐야지 하는 그런 사람은 없을 것이다.
좀 보기 좋게 연도별이라도 묶어보자(SQL에서 group by로 묶어주는 것 마냥).
df = pd.concat([s_2016, s_2017, s_2018], keys = [2016, 2017, 2018]) # 각데이터 프레임을 설정된 키값으로 묶어줌
keys = [] 여기에 변수 넣어주면, 이 변수명 대로 각각의 데이터 프레임을 묶어준다.
(key 값 빼먹은 데이터 프레임은 조인이 되지 않는다.

수평 결합
수평 결합을 하고 싶을 땐 concat 괄호 안에 axis = 1이라고 넣어주면 된다.
아깐 왜 0이라고 안 적었냐고요? 디폴트가 0이라서 수직 결합할 땐 생략 가능!
df2 = pd.concat([s_2016, s_2018], axis = 1)
df2
df3 = pd.concat([s_2016, s_2017], axis = 1) # full outer join(default)
df3
NaN이 생기는 이유는 디폴트가 full outer는 서로의 모든 행을 다 합치기 때문이다.
df4 = pd.concat([s_2016, s_2017], axis = 1, join = inner) # inner join 설정
df4
Inner join 하면 3개의 행에 맞춰서 join이 이루어져 Nan이 안 생기지만
정말 개수만 맞추는 것이기 때문에 의미가 없다.
위 결과를 보면 합쳐진 데이터의 Symbol이 일치하지 않는다.
Concat은 수직 결합에 주로 쓰인다고 생각하면 될 것 같다.
수평 결합 또한 정말 갖다 붙이는 용도라, 분리된 자료를 붙이고 싶을 때 사용하면 될 것 같습니다!
데이터 합체 목적은 각자 다- 다르기 때문에 용도에 맞게 골라 쓰는 건 열허분들의 몫!
03 Join
01 Join 기능
- dataframe 객체.join(others, how = 'left', lsuffix = ' ', rsuffix = ' ')
- 두개 이상의 Dataframe들 조인 가능
- df_A.join(df_b), df_A.join([df_b, df_c, df_d])
- 매개변수 lsuffix, rsuffix
- 조인대상 Dataframe에 같은 이름의 컬럼이 있으면 에러 발생
- 같은 이름이 있는 경우 붙일 접미어 지정
- how : 조인방식 'left', 'right', 'outer', 'inner' left가 기본
02 Join 코드(컬럼 기준)


s_info.join(s_2017)위의 두개의 데이터 프레임 합치고 싶다고, 이렇게 합치면 error 등장!
ValueError: columns overlap but no suffix specified: Index(['Symbol'], dtype='object')
columns 중복 되었으니 suffix 지정 안해줬다고 오류.
중복되는 column 있으면 join 불가. suffix 사용해서 이름을 바꿔줘야 해요!
s_info.join(s_2017, lsuffix = '_info', rsuffix = '_2017') ) # 데이터 프레임 각각에 이름 부여
왼쪽 데이터 프레임 컬럼 이름에 _info, 오른쪽 데이터 프레임 컬럼 이름에 _2017 각각 붙습니다.
그럼 error 없이 합체 가능!

03 Join 코드(인덱스 기준)
인덱스 기준 Join은, 합칠 데이터 프레임의 공통 열을 index로 만들어서 Join 하는 방법이다.
이 방법에선 set_index 코드를 사용해서, 우선 공통 열을 index로 설정하고 합! 체! 한다.
s_info.set_index('Symbol').join(s_2017.set_index('Symbol'), how = 'left')
03 3개 이상 Join
물론 3개 이상의 DF를 합칠 때도 한 줄에 주르르륵 쓸 수 있지만, 여러개의 데이터를 합칠 땐
다음와 같은 방법으로도 코드를 짤 수 있다!
others = [
s_2016.set_index('Symbol').add_suffix('_2016'), # add_suffix는 모든 컬럼에 접미사 부여
s_2017.set_index('Symbol').add_suffix('_2017'),
s_2018.set_index('Symbol').add_suffix('_2018')]
s_info.set_index('Symbol').join(others)합칠 DF들을 리스트 형태로 변수에 넣어주고, 메인 DF랑 합칠 땐 변수 이름으로 한번에 넣어준다!

- 각 DF 모두 Symbol을 index로 변경해서 index 기준으로 합체
- add_suffix 메소드 사용해서 각 DF의 모든 행에 접미사 add
☝️add_suffix
add_suffix는 메소드로 쩜 찍고 add_suffix 를 적어주고 괄호안에 접미사를 넣어준다.
s_2016_2.add_suffix('_2016') # 접미사가 뒤에 붙는다
s_2016_2.add_prefix('2016_') # 접미사가 앞에 붙는다
04 Merge
01 Merge 기능
- 두 개의 DataFrame 조인만 지원
- 조인 기준: 같은 컬럼명을 기준으로 equi-join이 기본. 조인 기준을 다양하게 정할 수 있음
- 조인 기본 방식: inner join
- dataframe.merge(합칠 dataframe, how = 'inner', on, index)
- 매개변수
- on: 같은 컬럼명이 여러개 일 때, join 대상 컬럼 선택
- right_on, left_on: 조인할 때 사용할 왼쪽, 오른쪽 DF의 컬럼명
- left_index, right_index: 조인할 때 index 사용할 경우 True로 지정
- how: 조인방식 'left', 'right', 'outer', 'inner' 기본: inner
- suffixes: 두 DF에 같은 이름의 컬럼명 있을 경우 구분 위해 붙일 접미어 리스트 생성
- 생략시 x, y를 자동으로 붙임
02 Merge 코드(on 결합)
s_2016.merge(s_2017, on = 'Symbol')
디폴트가 inner라 서로 공통된 행만 합쳐진다.
Merge는 on으로 설정 안해주면, 값이 모든 같은 열이 없기 때문에 아무 열도 나오지 않는다.
on 사용해서 기준이 될 컬럼을 지정해쥬자.
공통 이름을 가진 열들은 suffixes 설정 안해주면 x와 y가 자동으로 이름에 붙는다.
s_2016.merge(s_2017, on = "Symbol", suffixes = ['_2016', '_2017']) 리스트로 suffixes 부여
03 Merge 코드(index 결합)
Merge의 마지막으로 특정 열과 index를 지정해서 merge하는 방법을 알아boza.
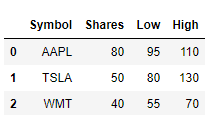

두 개의 데이터를 합 칠 때
s_2016는 symbol이라는 이름을 가진 열로, s_info_2는 index 를 기준으로 merge 해줘야 한다.
s_2016_2.merge(s_info_2,
left_on = 'Symbol', # 왼쪽 DF의 열 하나를 선택할 땐 left_on = '컬럼명'
right_index = True, # 오른쪽 DF의 index를 선택할 땐 right_index = True
how = 'left') # 왼쪽(s_2016)의 Symbol 컬럼과 오른쪽(s_info_2)의 index 명이 같은 행끼리 join. 방식: inner(default)
- left_on, right_on 사용해서 DF 지정해주고 컬럼명을 넣어준다
- left_index, right_index 를 True로 지정해주면 index를 기준으로 merge할 수 있다.
concat, join ,merge의 기능과 코드 사용방법을 배워보았다!
마지막으로 정리하자면
- 수직으로 합치는 경우(Union): concat()
- 두 개 이상 DF 조인: join()
- 두 개의 DF 조인할 때는 merge() -> 양 쪽 DF 컬럼과 인덱스를 지정할 수 있어 컨트롤이 편리, 공통 column 기준으로 join